
In the previous tutorial, we managed to set up a proper working environment with all the tools needed to start your journey into data science. If you have missed it, you can go back and learn about installing the right environment. Now that you’re ready, let’s get started.
DATA IS EVERYTHING
Data plays a crucial part in machine learning and understanding the right terminology when it comes to data will be important. In this tutorial, we will guide you through essential terminology and how to effectively speak about data, within the realm of machine learning. First, we are going to walk you through datasets, which will significantly help you with your understanding of machine learning algorithms.
CREATING A DATASET
As always, let’s jump into practice.
Head on to http://www.convertcsv.com/csv-viewer-editor.htm and use the grid to create a CSV file, as seen below:

Here, I have created a table with several European locations and distribution of salaries, based on age and occupation. However, the most interesting piece of data here is whether a person is self-employed or not. Ideally, we would like to have similarity patterns between location, age, salary, and occupation as well as understand what factors are key decision makers for those who decide to go into self-employment. In case you have just 11 rows like I do , it’s relatively easy to see and understand the pattern. However, now imagine having billions of rows of data. This is a dataset.
I think you get the point. And in talking about datasets, we have already covered the first in our machine learning terminology set; data points and features. What’s the difference, you ask? Easy, data points are the rows in the table, which means, in our example, we have 11 data points, and each data point has 4 features (Country, Age, Salary and Occupation).
Typically, we want to use the features to predict a numeric or categorical label. In our case, we can build a machine learning model that uses these 4 features and predicts the label of Self-Employed. Self-Employed is a categorical label, therefore our task is to make a binary classification. It’s binary because our target (Self-Employed) has two labels (yes and no).
IMPORTING LIBRARIES
For our next step, we will need to use libraries that we will install on Python to read and manipulate the data. Open Spyder IDE that you previously installed and create a new file. Name it however you prefer. I will name mine “data_prep_draft.py”.
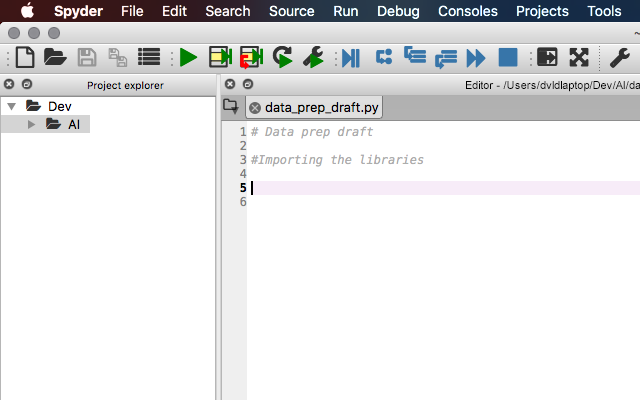
So why do we need to import a library? Well, first we need to understand what a library is. A library is a tool that you can utilize to complete a specific task. The benefit of a library is not having to write code that someone else has already written and tested. You can use code from the library. In our case, we just have to provide the specific input, and the library will return the desired output. During this set of tutorials, we are going to mostly use libraries. This will save time, make the machine learning models as efficient as possible, and hopefully make the learning process a bit more exciting
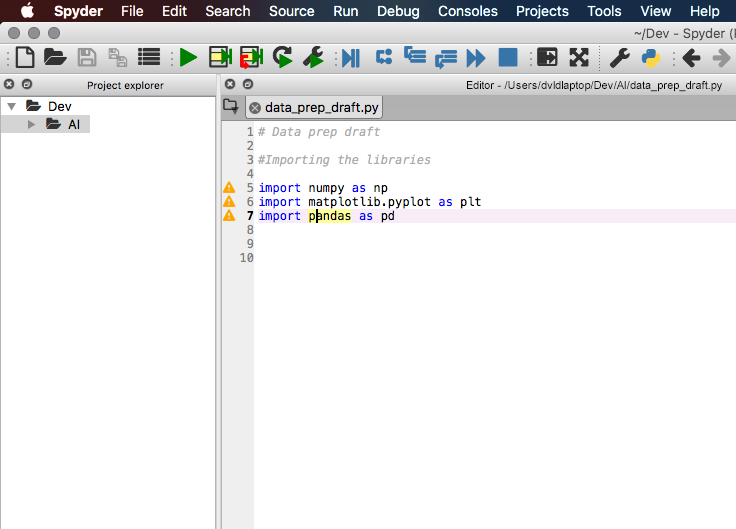
In my example I am going to use three essential libraries:
- Numpy – import it by typing import numpy and use its shortcut as np. Numpy is mostly used to perform math based operations during the machine learning process.
- Matplotlib – import the sublibrary “pyplot” by typing import matplotlib.pyplot. You can use it as a shortcut as plt. We will use this library to plot charts in python.
- Pandas – import the panda library and make a shortcut using import pandas as pd. We are going to use panda to import datasets and manage them.
As a result, you should be able to execute the imported libraries in spyder.
IMPORTING DATASETS
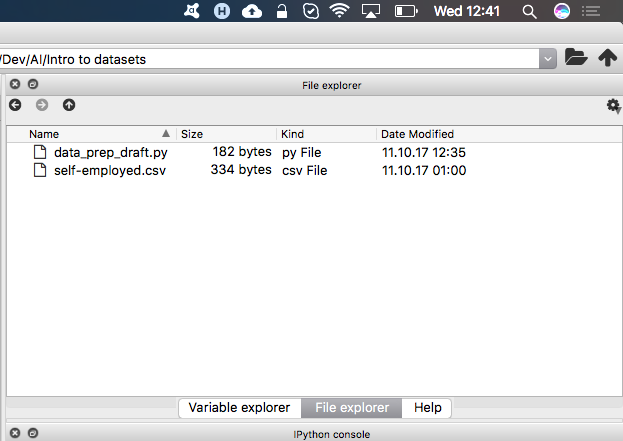
To set a working directory, you need to open your file explorer in Spyder and choose a target folder on your OS. I have placed the “data_prep_draft.py” file and previously created CSV file in a folder called “Intro to datasets” and pointed Spyder to read from that directory.
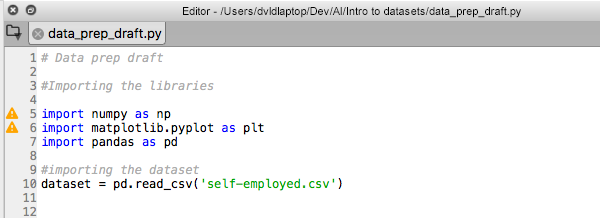
Declare a variable “dataset” and assign panda shortcut “PD” with its method “read_csv,” with a filename as a parameter to read the data from the CSV file in your working directory.
dataset = pd.read_csv('self_employed.csv')
To test if the function is working correctly, add a log statement by typing print("dataset") and head to the console on the right to see the output.
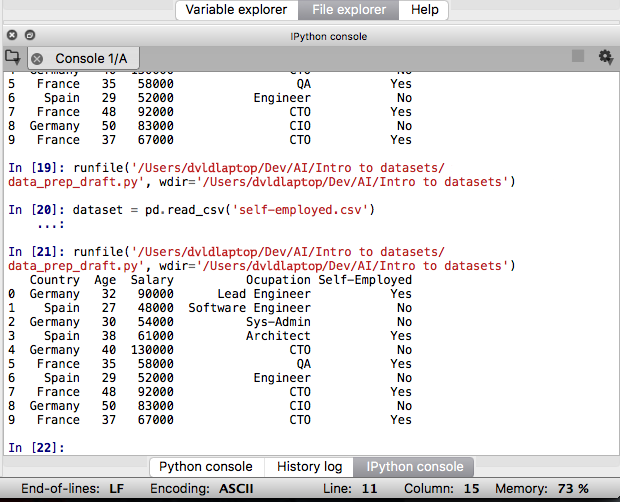
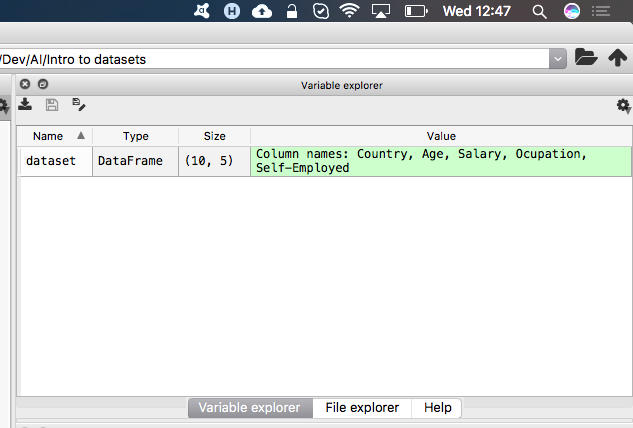
You can also double check in the variable explorer tab. That dataset is right there waiting for you to play with it.
If you double click on it, you can see the dataset in a nicely formatted way.
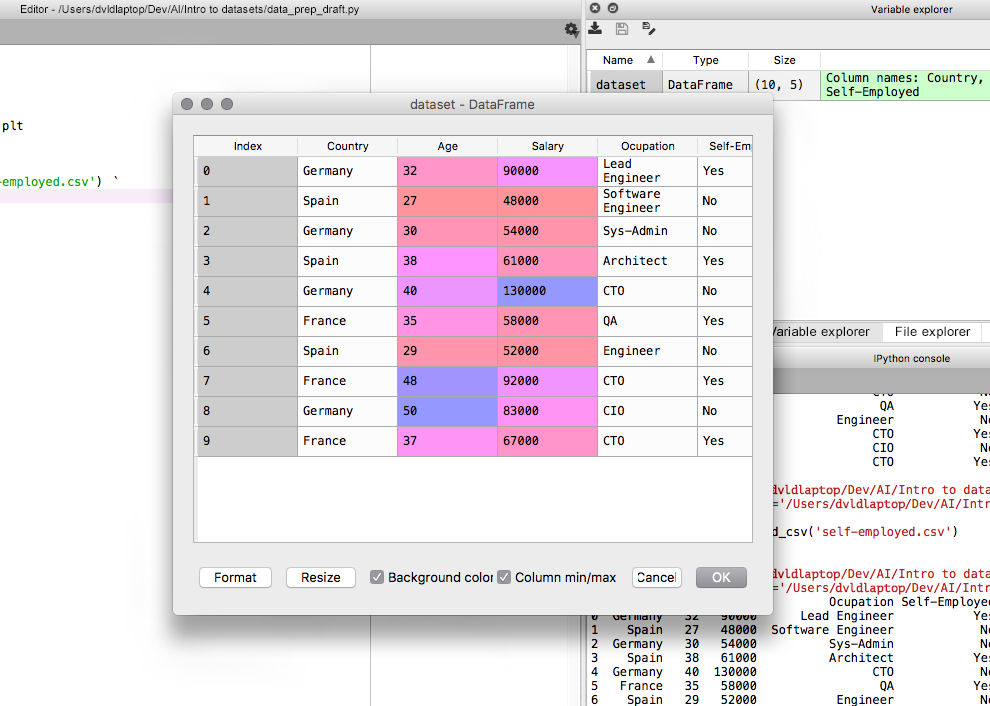
Do not be surprised if you see that indexing starts at zero, as that’s typical behavior for programming languages. I strongly suggest you go to ”kaggle.com” and find a dataset that interests you and load it into Python. You can just repeat the process above of downloading and loading data.
Here you can search through CSV datasets on kaggle:
www.kaggle.com/datasets?filetype=fileTypeCsv
That’s it for today, I hope you enjoyed it. In the next tutorial, we are going to go deeper into terminology and concepts. In addition, we’ll provide the basic theoretical and practical foundation of Machine learning.
- Topics:
- Artificial Intelligence

