
Develandoo continues to present a series of episodes from the Munich-AI Summit 2018 which took place on May 17th in Munich, Germany. The one-day summit gathered the brightest minds and thought leaders specialized in spheres of Artificial Intelligence, Data Science and Machine Learning in one place.
The Munich-AI Summit 2018 was the first and only AI related conference that took place in that area. In a previous article, we shared the purpose and content of the M-AI Summit, how you can benefit from attending it and why we should continue organising such events for free. In this episode, we are going to discuss the talk by Denis Krivitski on how recurrent neural networks are capable of generating poems, an interesting and catchy topic that became the centre of attention for more than 300 participants of the summit.

Chief technical officer of Avoncourt Partners GmbH, machine learning expert Denis Krivitski presented to the audience the basic and relatively simple structure and steps of how a neural network (NN) can generate poems. In other words, how through a neural network we can predict the content of the poem, that is to predict what a poet would write about that subject. We’re about to get into how this would work, but before we get started, let’s define what we call neural networks. They are the technology standing behind deep learning which is part of the machine learning discipline.
Now let’s go.
Minimizing losses through training NN
After rephrasing the issue of writing, into a large prediction problem, the next step is to break it down into smaller ones. The next step is to predict only one letter (character) that a poet would write following a given text.
Krivitski states that to predict the next character we need a neural network that can read any number of given characters, remember something about all of them, and then predict the next.
According to Krivitski, a good candidate for this kind of task is, what is called, a recurrent neural network (RNN).
First, let’s define what a recurrent neural network is. It is a neural network with a loop in them.
”It reads input one character at a time. After reading each character xt it generates an output ht and a state vector st. The state vector holds some information about all the characters that were read up until now and is passed to the next invocation of the recurrent network. The actual output does not match exactly the expected output as seen in the picture below. This is natural because otherwise, we would have an ideal network that predicts with perfect accuracy, which is not the case in practice. The difference between the expected and the actual prediction is called error or loss” explained Krivitski.
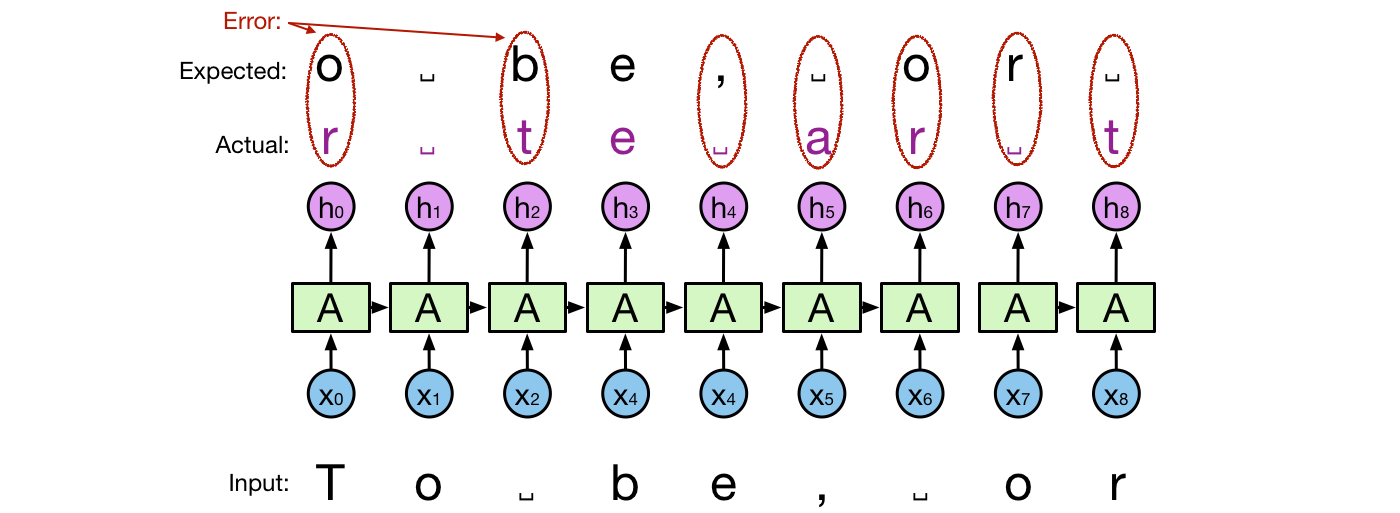
He further states that during training the NN is improved step by step to minimize loss. The training process uses training text to feed the network with pairs of input and expected output. Each time the actual output differs from the expected output, the parameters of the NN are corrected.
The picture below shows a sequence of predictions after different numbers of training steps.
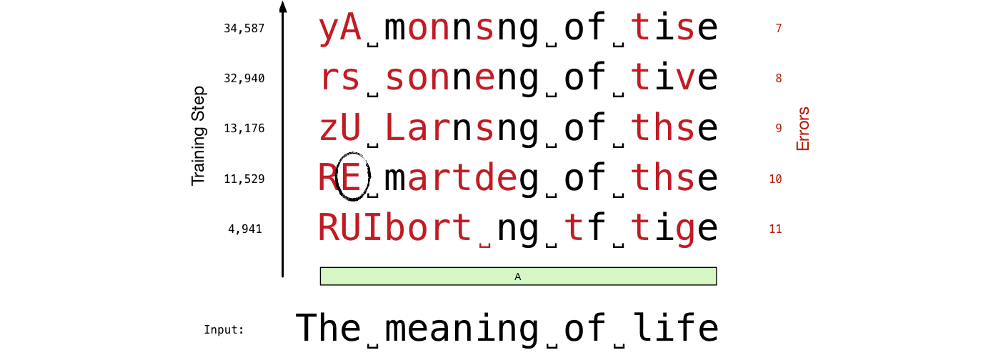
”Here, the input string is ”The meaning of life”. After 4,941 steps, we have 11 incorrectly predicted characters (marked in red). After 34,587 steps, the number of prediction errors fell to 7. We can see that more errors appear at the beginning of a string than at the end of a string. This is because by the end of the string the network reads more characters and its state contains richer information. This richer information leads to better and more informed predictions” says Krivitski.
Generation of the entire poem
At the beginning of his speech, Denis Krivitski focused on the smaller problem of predicting one character of a poem. Now it’s time to come back to the larger problem of generating the entire poem. In having a trained RNN at hand that can predict one character, we can employ the scheme depicted below to generate any number of characters.

First, the poem subject is provided as an input at x₀, x₁, x₂, … Outputs preceding h₀ are ignored. The first character that is predicted to follow the poem subject, h₀, is taken as the input to the next iteration. By taking the last prediction as the input for the next iteration we can generate as many characters as we desire. The left part of the network is an encoder that encodes the poem’s subject in a vector representation, called subject vector or theme vector. The right part of the network is a decoder that decodes the subject vector into a poem.
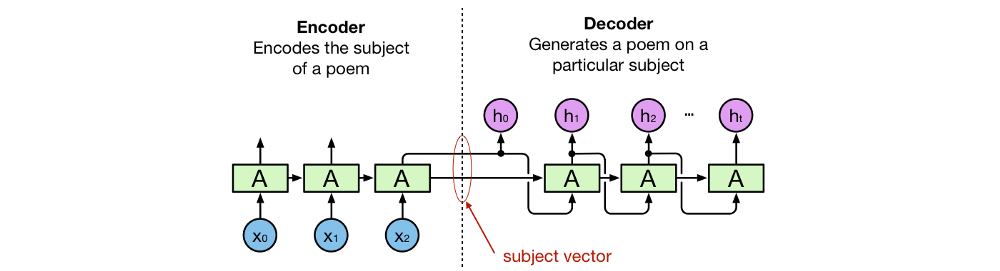
According to Krivitski, this perspective is used in machine translation systems. There an encoder encodes a sentence, in a source language, into a vector representing its meaning. Then, the decoder decodes the meaning vector, into a sentence, in a target language. Krivitski summed up his speech by turning to the audience with a message. He states that this is not the best possible neural network to generate the best poems. There are many ways to improve it. However, this is a simple neural network that achieves surprisingly good results.
”If you are a machine learning (ML) practitioner, understanding the structure of this network could give you ideas on how to use parts of this structure for your own ML task. If you are willing to start developing NN by yourself, recreating this network by yourself could be a good place to start. This network is simple enough to build from scratch, as well as complicated enough to require the usage and understanding of basic training techniques”.
We were super happy to have Denis Krivitski as a speaker at our M-AI 2018 Summit and to serve as a platform for discussions that, we believe, will pave the way for many young specialists who are just entering this challenging sphere of machine learning.
For the official video of Denis Krivitski’s talk check our youtube:
- Topics:
- Artificial Intelligence
- M-AI Summit

